
A large language model (LLM) is a deep learning system trained on vast amounts of text data that can understand and generate natural language. LLMs are the technology behind ChatGPT, Claude, Gemini, and virtually every AI writing tool used in content and marketing today.
Understanding what an LLM is and how it differs from AI broadly or from GPT specifically helps you make smarter decisions about which tools to use and how to work with them.
This guide covers the definition, how LLMs work, real-world examples, key capabilities, limitations, and how they compare to related terms like AI and GPT.
What Is a Large Language Model?
A large language model (LLM) is a type of artificial intelligence trained on massive amounts of text data and capable of understanding and generating human-like language across a wide range of tasks.
The word “large” refers to two distinct things at once: the scale of the training data and the size of the model itself. Training data for major LLMs is measured in hundreds of billions of words drawn from web pages, books, code, and scientific papers. Model size is measured in parameters, the internal numerical weights the model adjusts during training. GPT-3, released by OpenAI in 2020, has 175 billion parameters. Modern frontier models are substantially larger.
LLMs are built on the transformer architecture, introduced in the 2017 research paper “Attention Is All You Need” by researchers at Google. The transformer’s self-attention mechanism allows the model to weigh the relevance of every token to every other token in a sequence simultaneously, giving LLMs the ability to understand context across long passages of text in a way earlier language models could not.
The result is a system capable of understanding and generating coherent text, answering complex questions, summarizing documents, and adapting to dozens of task types from a single pretrained base.
How Does a Large Language Model Work?
LLMs work by repeatedly predicting the next token in a sequence, learning grammar, facts, reasoning patterns, and stylistic conventions from billions of training examples.
The process happens in three broad stages:

Step 1 — Pretraining on Massive Text Data
During pretraining, the model is exposed to a large corpus of text and trained to predict the next word (or token) in a sequence. It does this billions of times across diverse data sources.
GPT-3 was pretrained on roughly 570GB of filtered text, including data from Common Crawl (50+ billion web pages), WebText2, book corpora, and Wikipedia. Through this repetitive next-token prediction process, the model learns language structure, factual associations, logical relationships, and stylistic patterns without any labeled answers or explicit instruction. By the end of pretraining, the model has developed broad language capability but is not yet optimized for any specific task.
Step 2 — Fine-Tuning for Specific Tasks
Fine-tuning is a supervised training process in which a pretrained model is further trained on a smaller, task-specific dataset to adapt its behavior for a particular use. The model updates its weights using labeled examples, pairs of instructions and desired outputs, making it more useful in specific practical contexts.
A model fine-tuned for customer support will behave differently from a model fine-tuned for code generation or legal document summarization, even if both started from the same pretrained base. Fine-tuning allows organizations to customize a general-purpose LLM for their specific workflows without training a model from scratch.
Step 3 — RLHF (Reinforcement Learning from Human Feedback)
Reinforcement learning from human feedback (RLHF) is a refinement process used to shape how LLMs respond to user input. Human reviewers evaluate and rank different model outputs, and the model is trained to prefer the responses that human raters score more highly.
RLHF is why modern LLMs behave more like conversational assistants than raw text completion engines. Both OpenAI (ChatGPT) and Anthropic (Claude) rely on RLHF as a core alignment technique. The process makes models more helpful, reduces harmful outputs, and improves instruction-following without requiring new training data for every behavioral adjustment.
Examples of Large Language Models
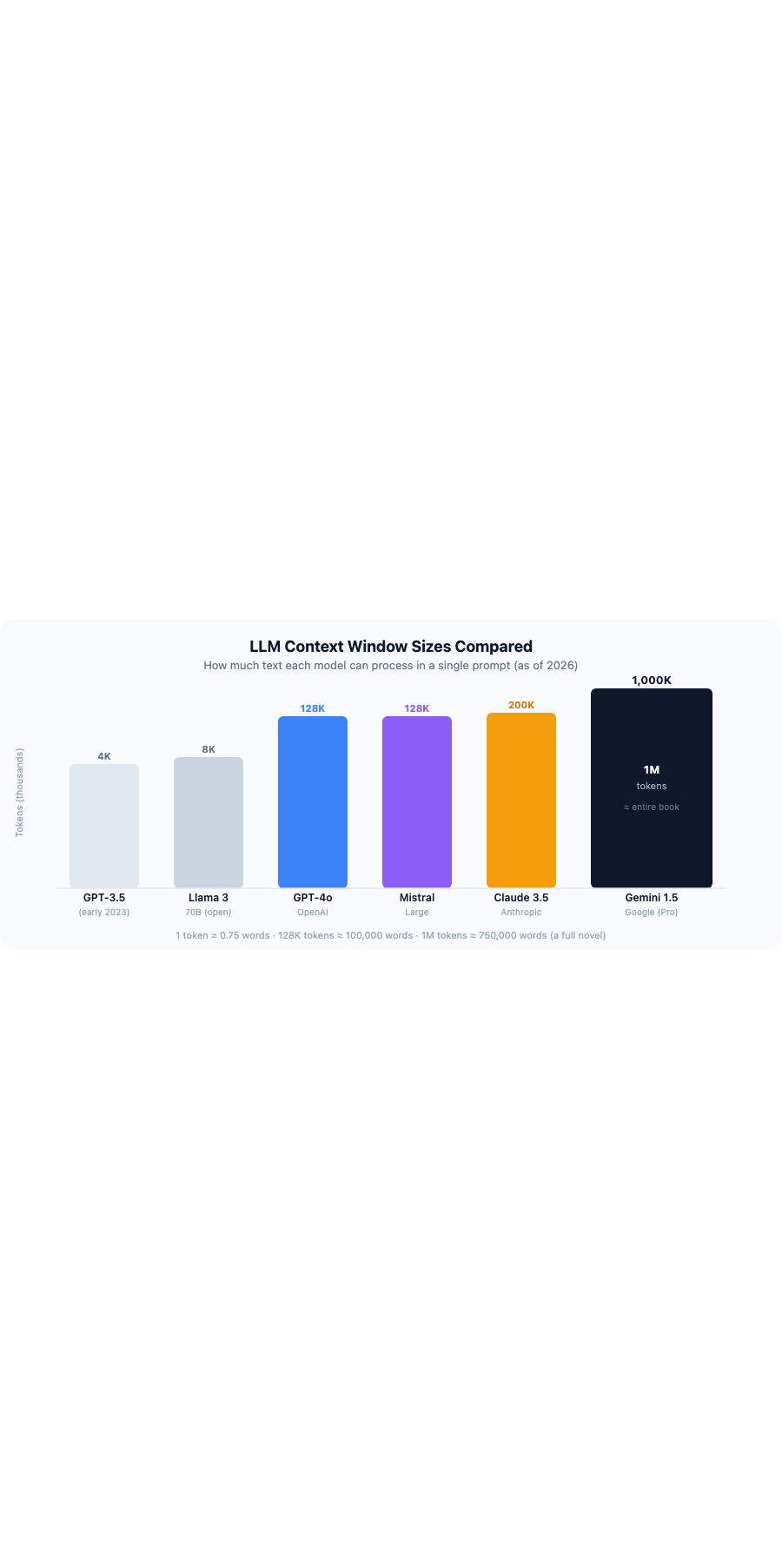
The most widely used large language models include GPT-4o (OpenAI), Claude 3.5 Sonnet (Anthropic), Gemini 1.5 Pro (Google), Llama 3 (Meta), and Mistral, each with different strengths, context windows, and licensing terms.
| Model | Maker | Parameters (est.) | Context Window | Best For | Open/Closed |
|---|---|---|---|---|---|
| GPT-4o | OpenAI | Undisclosed | 128K tokens | General tasks, multimodal input | Closed |
| Claude 3.5 Sonnet | Anthropic | Undisclosed | 200K tokens | Long documents, nuanced writing | Closed |
| Gemini 1.5 Pro | Undisclosed | 1M tokens | Large-context tasks, multimodal | Closed | |
| Llama 3 70B | Meta | 70B | 8K tokens | Open-source deployment | Open |
| Mistral Large | Mistral AI | Undisclosed | 128K tokens | Multilingual tasks, efficiency | Partially open |
One of the most significant recent developments in LLM capabilities is the expansion of context windows. Early GPT-3.5 models had a context window of roughly 4,096 tokens, meaning they could only process a few pages of text at a time. Gemini 1.5 Pro now supports over 1 million tokens, enough to process an entire book in a single prompt. Claude 3.5 Sonnet supports 200,000 tokens, making it well-suited for processing long reports, contracts, or research documents.
Open-source LLMs like Llama 3 and Mistral can be downloaded and run on your own infrastructure, giving teams full control over their data and no dependency on a third-party API. Closed-source LLMs like GPT-4o, Claude, and Gemini are accessible via API and are developed and maintained by their respective companies with ongoing safety and quality updates.
What Can a Large Language Model Do?
Large language models can generate text, summarize documents, translate languages, answer questions, write and debug code, and power conversational AI chatbots across dozens of task types.
Core capabilities include:
- Text generation — Write articles, emails, product descriptions, social posts, ad copy, and other content formats from a prompt
- Summarization — Condense long documents, reports, or research papers into concise outputs
- Translation — Translate between dozens of language pairs with high contextual accuracy
- Question answering — Retrieve and synthesize information from a provided context to answer specific questions
- Code generation — Write, complete, and debug code across languages like Python, JavaScript, and SQL
- Classification and sentiment analysis — Categorize content, detect tone, and label text at scale
- Conversational AI — Maintain context across multi-turn conversations to power customer support bots, virtual assistants, and AI agents
For content teams specifically, the most commonly reported enterprise applications are generating first drafts of text content (54% of enterprise AI users, McKinsey 2023), summarizing long documents (52%), and answering questions from internal knowledge bases (49%).
Understanding how to prompt LLMs effectively and when to apply human judgment on top of their output is becoming a core content skill. For teams thinking about how LLMs affect search visibility, our guide to LLM SEO covers the topic in depth.
LLM vs. AI vs. GPT: What’s the Difference?
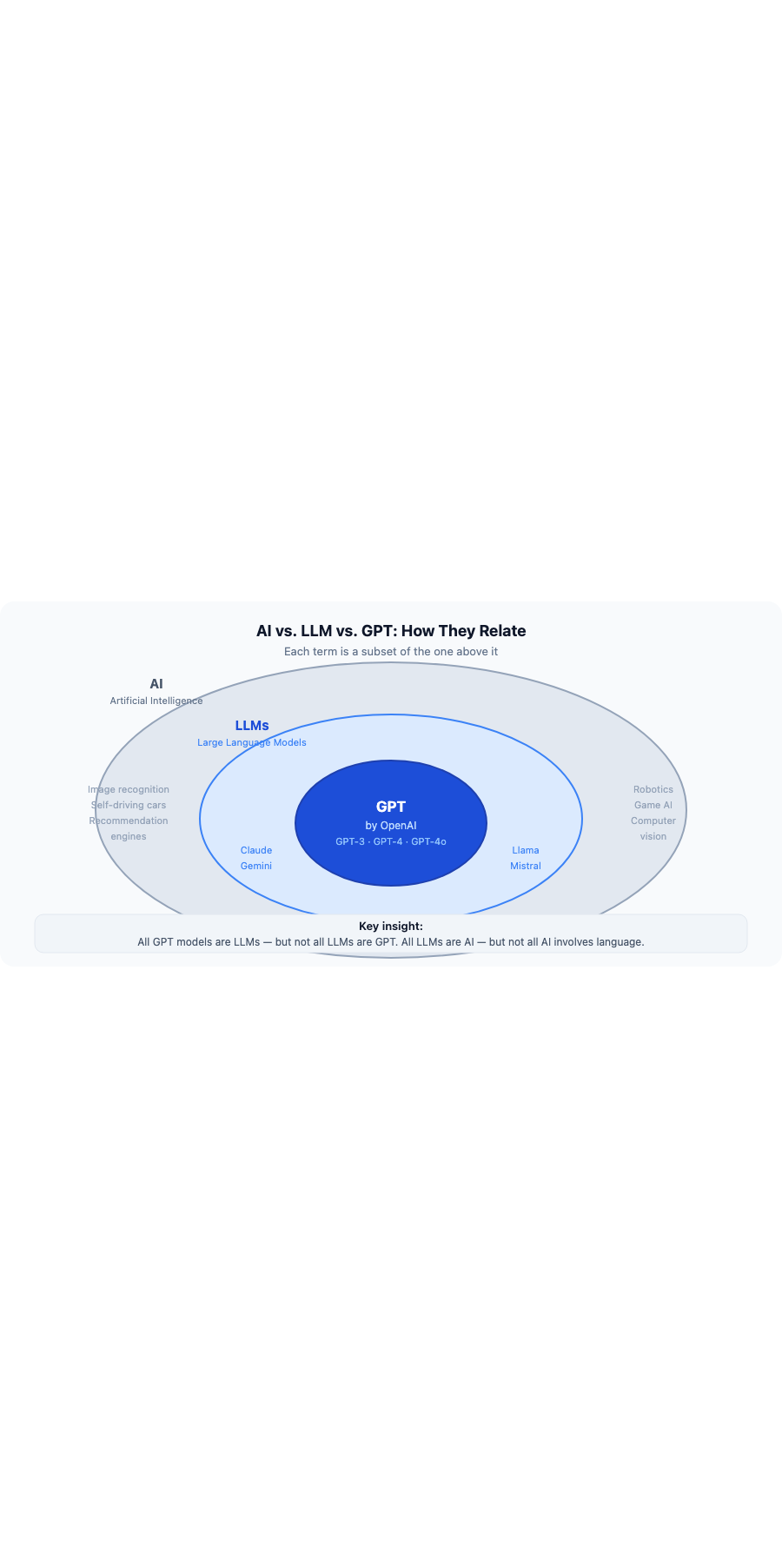
AI is the broad field; LLMs are a category of AI focused on language; GPT is a specific LLM series made by OpenAI. All GPT models are LLMs, but not all LLMs are GPT.
A useful analogy: if AI is the category “smartphones,” then LLMs are “a type of smartphone” and GPT is one specific brand within that category.
| Term | What It Is | Examples |
|---|---|---|
| AI (Artificial Intelligence) | Broad field covering any system that simulates human intelligence | Self-driving cars, recommendation engines, image recognition, LLMs |
| LLM (Large Language Model) | A type of AI trained on text data to understand and generate language | GPT-4o, Claude, Gemini, Llama, Mistral |
| GPT (Generative Pre-trained Transformer) | A specific LLM series developed by OpenAI | GPT-3, GPT-3.5, GPT-4, GPT-4o |
GPT is an acronym for Generative Pre-trained Transformer. Each word describes a core property of the model: it generates text (Generative), was trained on unlabeled data before task-specific fine-tuning (Pre-trained), and uses the transformer neural network architecture (Transformer). The first GPT model was released by OpenAI in 2018.
LLM vs. NLP: Natural language processing (NLP) is the older, broader field concerned with making computers work with human language. LLMs are a modern, highly capable subset of NLP. Earlier NLP models used rule-based systems and statistical methods. LLMs use deep learning at a scale that makes them dramatically more flexible and capable across open-ended tasks.
LLM vs. Chatbot: A chatbot is an application; an LLM is the technology that powers it. ChatGPT is a chatbot built on GPT-4o. Claude.ai is a chatbot built on Claude 3.5 Sonnet. The LLM is the engine; the chatbot is the user-facing interface.
Limitations of Large Language Models
Large language models have four key limitations: hallucinations (generating false information confidently), training data bias, knowledge cutoff dates, and reasoning gaps on complex multi-step problems.
- Hallucinations — LLMs generate text by predicting what sounds plausible based on training patterns, not by verifying facts against a reliable source. When the model lacks sufficient training signal for a query, it may produce confident-sounding but factually incorrect output, such as citing a study that does not exist or attributing a quote to the wrong person. A 2023 study found hallucination rates ranging from 3% to 27% across major LLMs depending on the task type. Always verify factual claims in LLM-generated content before publishing.
- Training data bias — LLMs inherit the biases present in their training data. If the source text overrepresents certain viewpoints, demographics, or languages, the model’s outputs will reflect those imbalances. This can affect tone, framing, and representation in generated content in ways that are not always visible without deliberate review.
- Knowledge cutoff — LLMs are trained on data up to a specific date and have no awareness of events after that point. Asking a model about recent news, newly launched products, or post-cutoff statistics will produce outdated or invented answers unless the model has access to a live retrieval system such as retrieval-augmented generation (RAG).
- Reasoning limitations — While LLMs perform well on many reasoning tasks, they can struggle with multi-step math, formal logic, and tasks that require precise step-by-step verification. Newer reasoning models such as OpenAI’s o1 and o3 series address this partially through chain-of-thought training, but the limitation remains relevant for complex analytical work.
For AI-generated content used in SEO and search, these limitations have direct implications for content accuracy, freshness, and trustworthiness. Our guide to AI visibility covers how search engines and AI systems evaluate these qualities.
Frequently Asked Questions About Large Language Models
What does LLM stand for?
LLM stands for large language model. The term refers to a deep learning model trained on large quantities of text data to understand and generate human language. In academic and legal contexts, “LLM” can also stand for “Master of Laws” (Legum Magister), which is unrelated to AI.
Is ChatGPT an LLM?
ChatGPT is an AI chatbot powered by an LLM (specifically GPT-4o). The LLM is the underlying language model; ChatGPT is the product interface built on top of it. Other chatbots powered by LLMs include Claude (Anthropic), Gemini (Google), and Copilot (Microsoft, also built on GPT-4).
What is the difference between an LLM and a foundation model?
A foundation model is a large pretrained model that serves as a general-purpose base for many downstream tasks. LLMs are a type of foundation model specifically trained on text data. Other foundation models include vision models, audio models, and multimodal models that process images or audio alongside text. All LLMs are foundation models, but not all foundation models are LLMs.
Are LLMs the same as generative AI?
No. Generative AI is a broader category that includes any AI system capable of generating new content, including images, audio, video, code, or text. LLMs are a type of generative AI focused specifically on text. An image generator like DALL-E or Midjourney is also generative AI but is not an LLM.
What is the best LLM for content creation?
The answer depends on the specific use case. Claude 3.5 Sonnet is widely used for long-form writing and document analysis because of its 200K token context window and strong instruction-following. GPT-4o performs well on general tasks and multimodal inputs. Gemini 1.5 Pro is useful when processing large volumes of text in a single prompt. For teams that need to run their own infrastructure without an API dependency, Llama 3 is the leading open-source option.