
Technisches SEO umfasst alle Maßnahmen, die sicherstellen, dass Suchmaschinen eine Website korrekt crawlen, indexieren und verstehen können. Es bildet das Fundament jeder SEO-Strategie. Ohne solide technische Basis helfen auch der beste Content und starke Backlinks nur wenig. Wer technische Fehler ignoriert, verschenkt Ranking-Potenzial, das er sich mit anderen Maßnahmen mühsam erarbeitet hat.
Was ist technisches SEO?
Technisches SEO ist der Teilbereich der Suchmaschinenoptimierung, der sich mit der technischen Infrastruktur einer Website befasst. Ziel: Crawlern wie Googlebot den Zugang zu allen relevanten Seiten ermöglichen und korrekte Indexierung sicherstellen. Damit unterscheidet es sich klar von OnPage-SEO (Inhalte und Keywords) und OffPage-SEO (externe Verlinkung).
| Bereich | Fokus | Beispiel-Maßnahmen |
|---|---|---|
| Technisches SEO | Infrastruktur und Zugänglichkeit | robots.txt, XML-Sitemap, HTTPS, Core Web Vitals, Crawling |
| OnPage-SEO | Inhalt und Seitenoptimierung | Meta-Titel, Überschriften, Keywords, interne Links, Textqualität |
| OffPage-SEO | Externe Signale und Autorität | Backlinks, Brand Mentions, Social Signals, Gastbeiträge |
Die fünf Kernaufgaben des technischen SEO:
- Crawlbarkeit sicherstellen: Suchmaschinen-Crawler müssen alle wichtigen Seiten ungehindert erreichen können
- Indexierung steuern: Bestimmen, welche Seiten in den Suchindex aufgenommen werden und welche nicht
- Ladezeiten optimieren: Core Web Vitals verbessern, um Ranking-Vorteile und bessere Nutzererfahrung zu erzielen
- Mobile-Freundlichkeit gewährleisten: Googlebot bewertet Websites primär anhand der mobilen Version
- Technische Markup-Signale setzen: Canonical Tags, strukturierte Daten und hreflang korrekt implementieren
Was gehört zum technischen SEO? Die 7 Kernbereiche
Sieben Kernbereiche prägen das technische SEO: Crawling und Indexierung, Website-Struktur und URL-Architektur, Page Speed und Core Web Vitals, Mobile Optimierung, HTTPS und Website-Sicherheit, strukturierte Daten und Schema.org sowie Duplicate Content und Canonicalisierung. Jeder dieser Bereiche beeinflusst direkt, wie gut Seiten in den Suchergebnissen abschneiden.
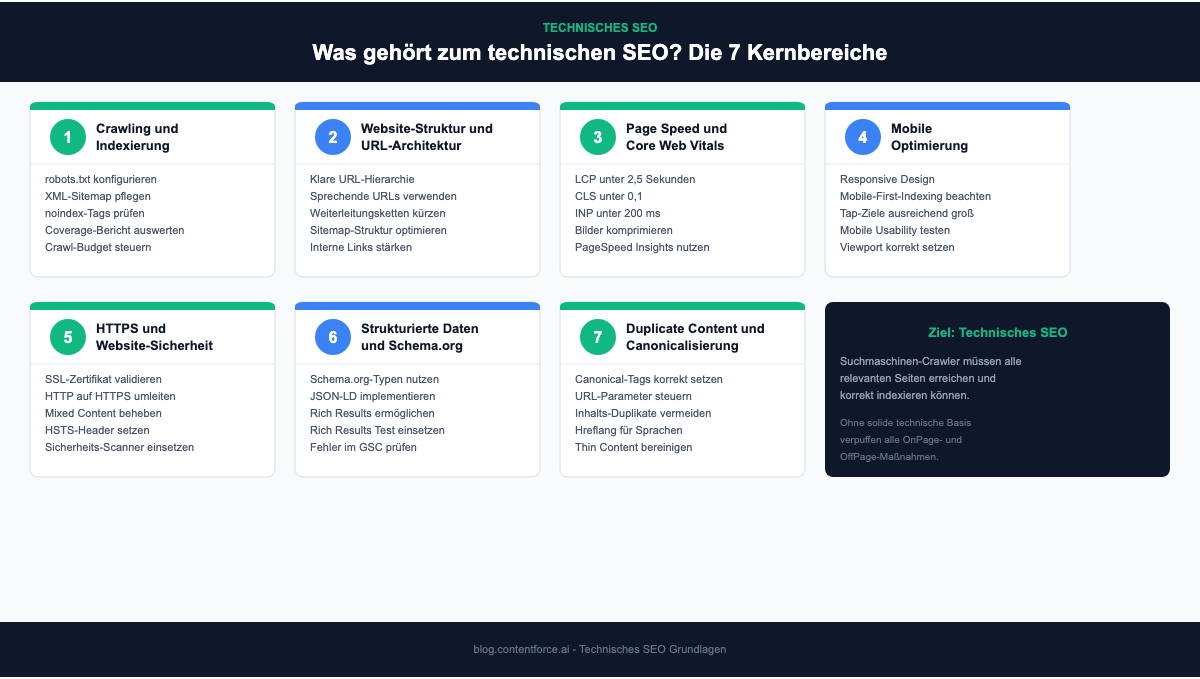
1. Crawling und Indexierung
Kein organisches Ranking ohne Crawling und Indexierung. Wenn Googlebot Seiten nicht erreicht oder nicht in den Index aufnimmt, nützt alles andere nichts. Das ist keine Übertreibung, sondern der technische Ausgangspunkt jeder SEO-Arbeit.
Konkrete Maßnahmen:
- robots.txt prüfen: Die Datei unter yourdomain.de/robots.txt darf keine wichtigen Verzeichnisse oder CSS/JS-Dateien blockieren. Ein versehentliches `Disallow: /` sperrt Googlebot komplett aus.
- XML-Sitemap einreichen: Die Sitemap sollte alle indexierbaren Seiten enthalten und in der Google Search Console unter „Sitemaps“ hinterlegt sein. Sie darf keine 404-Seiten oder noindex-URLs enthalten.
- Crawl-Budget beachten: Bei großen Websites ab ca. 1.000 Seiten sollte sichergestellt werden, dass Googlebot sein Budget nicht an Parametern, Facettierungen oder doppelten URLs verschwendet.
- Indexierungsstatus kontrollieren: Der Coverage-Bericht in der Google Search Console zeigt, welche Seiten indexiert sind und welche mit welcher Begründung ausgeschlossen wurden.
- Noindex-Tags prüfen: Tags, die versehentlich von der Staging-Umgebung übernommen wurden, schließen wichtige Seiten dauerhaft aus dem Index aus.
2. Website-Struktur und URL-Architektur
Eine durchdachte Website-Struktur sorgt dafür, dass Crawler wichtige Seiten schnell finden. Link-Autorität fließt dann effizient durch die gesamte Website, statt in Sackgassen zu versickern.
Konkrete Maßnahmen:
- Klicktiefe begrenzen: Wichtige Seiten sollten maximal drei Klicks von der Startseite entfernt sein. Tiefer vergrabene Seiten werden seltener gecrawlt und erhalten weniger interne Autorität.
- URLs sauber halten: Kurze, beschreibende URLs mit Bindestrichen statt Unterstrichen. Sonderzeichen, Session-IDs und unnötige Parameter gehören nicht in die URL-Struktur.
- Interne Verlinkung optimieren: Kontextuelle Links im Fließtext helfen Crawlern, thematisch verwandte Seiten zu entdecken. Ankertexte sollten beschreibend sein und das Zielkeyword enthalten.
- Verwaiste Seiten vermeiden: Seiten ohne eingehende interne Links werden selten gecrawlt und erhalten keine interne Link-Autorität.
- Weiterleitungsketten auflösen: Jede zusätzliche Weiterleitung kostet Crawl-Budget und Link-Equity. Wenn A auf B zeigt, das auf C zeigt, sollte A direkt auf C zeigen.
3. Page Speed und Core Web Vitals
Google nutzt die Core Web Vitals als direkten Ranking-Faktor. Schlechte Werte kosten nicht nur Rankings, sie vertreiben auch Nutzer, bevor diese mit dem Inhalt interagieren. Beides lässt sich messen, beides lässt sich beheben.
Die aktuellen Core Web Vitals und ihre Schwellenwerte:
| Metrik | Gut | Verbesserungsbedarf | Schlecht |
|---|---|---|---|
| Largest Contentful Paint (LCP) | unter 2,5 s | 2,5 bis 4 s | über 4 s |
| Interaction to Next Paint (INP) | unter 200 ms | 200 bis 500 ms | über 500 ms |
| Cumulative Layout Shift (CLS) | unter 0,1 | 0,1 bis 0,25 | über 0,25 |
INP hat seit März 2024 den alten First Input Delay (FID) als Core Web Vital abgelöst. Es misst die Latenz aller Interaktionen auf einer Seite, nicht nur die erste, und ist damit ein strengeres Signal.
Konkrete Maßnahmen:
- Bilder in modernen Formaten ausliefern: WebP oder AVIF reduzieren Dateigrößen spürbar ohne sichtbare Qualitätsverluste. Das verbessert direkt den LCP-Wert.
- LCP-Element priorisieren: Das wichtigste sichtbare Element (meist Hero-Bild oder großer Textblock) sollte mit `fetchpriority=“high“` und einem Preload-Link im Head geladen werden.
- JavaScript-Ausführung steuern: Lange JavaScript-Aufgaben über 50 ms blockieren den Main Thread und verschlechtern den INP. Nicht kritische Scripts sollten auf `defer` gesetzt werden.
- Layoutverschiebungen verhindern: Bilder und Videos brauchen explizite Breiten- und Höhenangaben, damit der Browser den Platz reserviert, bevor das Element geladen ist. Das hält CLS unter 0,1.
- Server-Antwortzeiten verkürzen: Ein CDN reduziert die Latenz für Nutzer, die weit vom Ursprungsserver entfernt sind.
4. Mobile Optimierung
Google verwendet Mobile-First-Indexing. Die mobile Version einer Website ist die Grundlage für alle Ranking-Entscheidungen, auch bei Desktop-Suchanfragen. Eine mobile Version, die schlechter ist als die Desktop-Version, drückt das Ranking für alle Geräte nach unten.
Konkrete Maßnahmen:
- Viewport-Meta-Tag setzen: Jede Seite braucht `<meta name=“viewport“ content=“width=device-width, initial-scale=1″>`. Ohne diesen Tag rendern mobile Browser eine verkleinerte Desktop-Ansicht.
- Schriftgröße anpassen: Fließtext sollte auf mobilen Geräten mindestens 16 px groß sein, um ohne Zoom lesbar zu sein.
- Touch-Ziele ausreichend groß gestalten: Klickbare Elemente wie Buttons und Links sollten mindestens 48 x 48 px groß sein und ausreichend Abstand voneinander haben.
- Inhaltsparität sicherstellen: Inhalte, die nur auf dem Desktop sichtbar sind, bewertet Google nicht. Alle wichtigen Texte, Bilder und Links müssen auch in der mobilen Ansicht vorhanden sein.
- Mobile Usability-Bericht nutzen: Die Google Search Console listet unter „Mobile Benutzerfreundlichkeit“ alle Seiten auf, die mobile Probleme aufweisen.
5. HTTPS und Website-Sicherheit
Seit 2014 ist HTTPS ein Ranking-Signal von Google. Browser zeigen auf HTTP-Seiten Sicherheitswarnungen an, die das Nutzervertrauen und die Klickrate senken. Für wettbewerbsfähige Platzierungen ist HTTPS schlicht Pflicht.
Konkrete Maßnahmen:
- SSL-Zertifikat prüfen: Ein abgelaufenes oder falsch konfiguriertes Zertifikat löst Browser-Warnungen aus. Das Zertifikat muss gültig sein und automatisch erneuert werden.
- HTTP auf HTTPS umleiten: Alle HTTP-Versionen der Seiten müssen per 301-Weiterleitung auf die HTTPS-Version zeigen.
- Mixed-Content-Fehler beheben: Wenn eine HTTPS-Seite Ressourcen über HTTP lädt, warnen Browser oder blockieren diese Ressourcen. Die Console in den Chrome DevTools zeigt entsprechende Meldungen.
- HSTS-Header setzen: HTTP Strict Transport Security verhindert, dass Browser die unverschlüsselte HTTP-Version anfragen.
- www- und non-www-Version vereinheitlichen: Genau eine Version sollte kanonisch sein; die andere leitet per 301 um.
6. Strukturierte Daten und Schema.org
Strukturierte Daten sind maschinenlesbare Markierungen im HTML-Code, die Suchmaschinen erklären, was eine Seite inhaltlich bedeutet. Korrekte Implementierung erhöht die Chance auf Rich Results in den Suchergebnissen erheblich.
Konkrete Maßnahmen:
- JSON-LD bevorzugen: Google empfiehlt JSON-LD als Format, weil es sich leicht pflegen lässt und vom restlichen HTML-Code getrennt ist.
- Article-Schema setzen: Für redaktionelle Inhalte sollte das Schema Autor, Veröffentlichungsdatum und Publisher enthalten.
- FAQPage-Schema nutzen: Seiten mit Frage-Antwort-Abschnitten können als Rich Results erscheinen, wenn FAQPage-Markup korrekt implementiert ist.
- BreadcrumbList implementieren: Breadcrumb-Schema hilft Google, die Seitenstruktur zu verstehen, und zeigt die Navigation direkt in den Suchergebnissen an.
- Rich Results Test verwenden: Alle Schema-Implementierungen sollten mit dem Rich Results Test von Google auf Fehler geprüft werden.
7. Duplicate Content und Canonicalisierung
Duplicate Content entsteht, wenn identischer oder sehr ähnlicher Inhalt unter mehreren URLs erreichbar ist. Das verschwendet Crawl-Budget, verwässert Link-Equity und kann dazu führen, dass Google die falsche Version einer Seite indexiert.
Konkrete Maßnahmen:
- Canonical Tags auf allen indexierbaren Seiten setzen: Jede Seite sollte einen `rel=“canonical“`-Tag enthalten, der auf die bevorzugte URL zeigt. Self-referencing Canonicals bestätigen Google, dass die aktuelle Seite die autoritative Version ist.
- URL-Varianten vereinheitlichen: Versionen mit und ohne Trailing Slash, mit http vs. https sowie www vs. non-www müssen per 301 auf eine kanonische URL umgeleitet werden.
- URL-Parameter kontrollieren: Facettierungen und Filter-Parameter auf E-Commerce-Seiten erzeugen oft hunderte URLs ohne einzigartigen Inhalt. Diese sollten in der Google Search Console konfiguriert oder per robots.txt blockiert werden.
- Canonical auf nicht-umleitende URLs prüfen: Ein Canonical, der auf eine URL zeigt, die selbst weiterleitet, schwächt das Signal. Canonicals müssen immer auf die finale, direkt erreichbare URL zeigen.
Technisches SEO Audit durchführen: Die 7 Schritte
Ein technisches SEO Audit prüft systematisch alle technischen Bereiche einer Website und identifiziert Probleme, die das Ranking behindern. Crawl-Probleme müssen dabei vor Performance-Optimierungen behoben sein, denn es hat wenig Sinn, Ladezeiten zu tunen, solange Googlebot wichtige Seiten gar nicht findet.
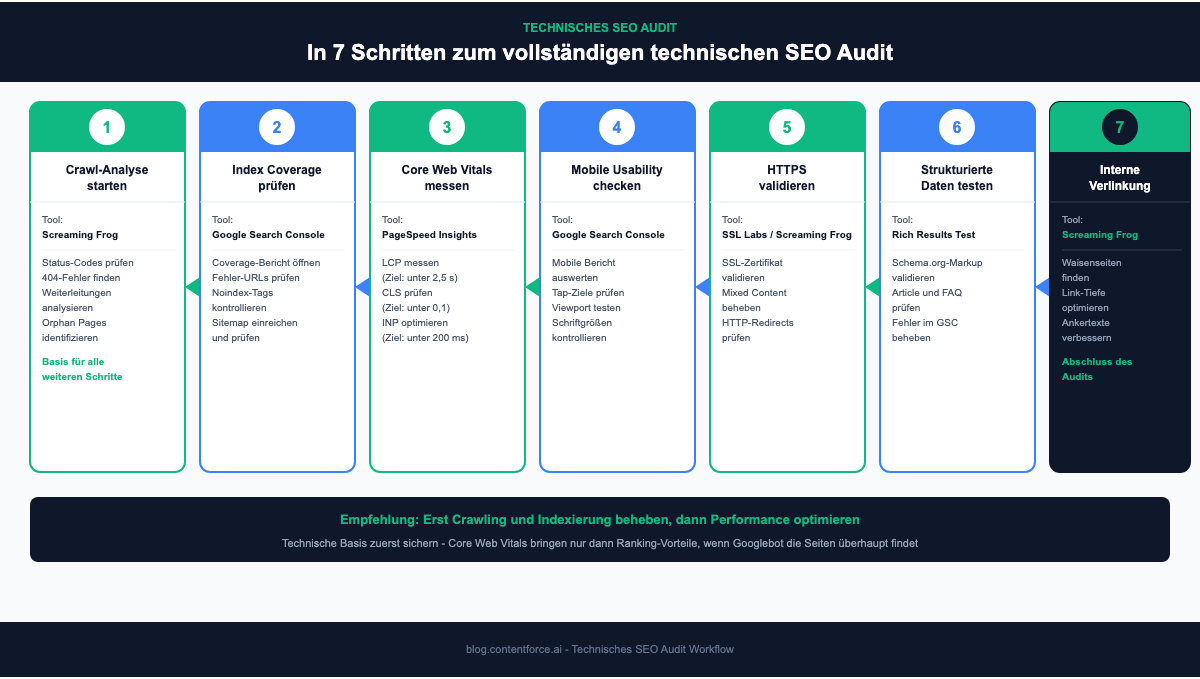
Schritt 1: Crawl-Analyse starten
Tool: Screaming Frog SEO Spider (kostenlos bis 500 URLs)
Starten Sie einen vollständigen Crawl mit Screaming Frog. Das Tool simuliert Googlebot und listet alle gefundenen URLs mit Status-Codes, Meta-Daten, Überschriften und internen Links auf. Achten Sie auf:
- Seiten, die 404-Fehler zurückgeben und intern verlinkt sind
- Weiterleitungsketten mit mehr als einem Hop
- Seiten mit fehlenden oder doppelten Meta-Titeln und Meta-Beschreibungen
- Verwaiste Seiten, die im Crawl nicht auftauchen, aber in der Sitemap stehen
Der Screaming-Frog-Crawl ist die Grundlage für fast alle weiteren Audit-Schritte. Exportieren Sie die Ergebnisse als CSV, um sie später mit anderen Datenquellen abgleichen zu können.
Schritt 2: Index Coverage prüfen
Tool: Google Search Console (kostenlos)
Öffnen Sie in der Google Search Console den Bericht „Indexabdeckung“. Er zeigt, welche Seiten Google indexiert hat und welche mit welcher Begründung ausgeschlossen wurden. Wichtige Kategorien:
- „Gecrawlt, aber nicht indexiert“: Google hat die Seite gefunden, hält sie aber nicht für indexierungswürdig. Mögliche Ursache: dünner Inhalt oder Duplicate Content.
- „Durch robots.txt blockiert“: Prüfen Sie, ob diese Blockierung beabsichtigt war.
- „Noindex-Tag“: Bestätigen Sie, dass diese Seiten bewusst ausgeschlossen sind. Noindex-Tags, die versehentlich von der Staging-Umgebung übernommen wurden, sind ein häufiger Fehler.
- „Weiterleitungsfehler“: Seiten, deren Weiterleitung nicht funktioniert, verschwinden aus dem Index.
Gleichen Sie die ausgeschlossenen Seiten mit Ihrer Sitemap ab. URLs, die sowohl in der Sitemap als auch in der Ausgeschlossen-Liste erscheinen, müssen untersucht werden.
Schritt 3: Core Web Vitals messen
Tool: Google PageSpeed Insights (kostenlos), Google Search Console
Rufen Sie Google PageSpeed Insights auf und testen Sie die wichtigsten Seiten: mindestens Startseite, wichtigste Kategorie-Seite und einen repräsentativen Artikel. Das Tool zeigt sowohl Labor-Daten (Lighthouse) als auch Felddaten von echten Chrome-Nutzern. Für Ranking-Entscheidungen verwendet Google die Felddaten.
Prüfen Sie:
- LCP unter 2,5 s? Falls nicht: Welches Element ist der LCP-Auslöser?
- CLS unter 0,1? Falls nicht: Welche Elemente verschieben das Layout?
- INP unter 200 ms? Falls nicht: Welche JavaScript-Aufgaben blockieren den Main Thread?
In der Google Search Console finden Sie unter „Core Web Vitals“ eine Übersicht aller Seiten, gruppiert nach Gut, Verbesserungsbedarf und Schlecht.
Schritt 4: Mobile Usability checken
Tool: Google Search Console (kostenlos)
Öffnen Sie den Bericht „Mobile Benutzerfreundlichkeit“ in der Google Search Console. Er listet alle Seiten auf, die mobile Probleme aufweisen. Die häufigsten Fehler:
- Text zu klein zum Lesen (Basis-Schriftgröße unter 16 px)
- Klickbare Elemente zu dicht beieinander (Touch-Ziele unter 48 x 48 px)
- Inhalte breiter als der Bildschirm (Elemente mit fixer Breite, die auf kleinen Displays Horizontal-Scrollen erzwingen)
- Fehlender Viewport-Meta-Tag
Prüfen Sie zusätzlich manuell auf einem Smartphone, ob alle wichtigen Inhalte in der mobilen Version sichtbar sind.
Schritt 5: HTTPS validieren
Tool: Browser und Chrome DevTools (kostenlos)
Laden Sie die Startseite und typische Unterseiten in Chrome und prüfen Sie:
- Zeigt die Adressleiste ein Schloss-Symbol? Falls nicht, liegt ein SSL-Problem vor.
- Öffnen Sie DevTools (F12): Sehen Sie unter „Console“ oder „Security“ Mixed-Content-Warnungen?
- Leitet `http://ihredomain.de` auf `https://ihredomain.de` um?
- Prüfen Sie das Ablaufdatum des SSL-Zertifikats über das Schloss-Symbol in der Adressleiste.
Tools wie Sistrix oder Screaming Frog können HTTPS-Probleme seitenübergreifend automatisch erkennen.
Schritt 6: Strukturierte Daten testen
Tool: Google Rich Results Test (kostenlos)
Testen Sie die wichtigsten Seitentypen auf korrekte Schema-Implementierung. Rufen Sie den Rich Results Test von Google auf und geben Sie die URL ein. Das Tool zeigt:
- Welche Schema-Typen erkannt wurden
- Fehler, die eine Qualifikation für Rich Results verhindern
- Warnungen, die die Schema-Qualität beeinträchtigen
Prüfen Sie mindestens eine Artikel-Seite (Article/BlogPosting), eine FAQ-Seite (FAQPage) und die Startseite (Organization). Fehler in strukturierten Daten verhindern keine Indexierung, blockieren aber Rich Results.
Schritt 7: Interne Verlinkung analysieren
Tool: Screaming Frog SEO Spider, Google Search Console
Gehen Sie in Screaming Frog zum Tab „Bulk Export“ und exportieren Sie alle internen Links. Prüfen Sie:
- Gibt es Seiten ohne eingehende interne Links? Diese sind Kandidaten für Orphan-Page-Fixes.
- Zeigen interne Links auf 404-Seiten oder Weiterleitungs-URLs statt direkt auf die Ziel-URL?
- Sind die Ankertexte beschreibend oder generisch?
- Sind die wichtigsten Seiten innerhalb von drei Klicks von der Startseite erreichbar?
Die Google Search Console zeigt unter „Links“ die meistverknüpften internen Seiten und welche Seiten die meisten eingehenden Links erhalten.
Die besten Tools für technisches SEO
Für die Grundausstattung braucht es drei Tools: Google Search Console für Indexierungs- und Crawling-Daten, Screaming Frog für den vollständigen Website-Crawl und Google PageSpeed Insights für die Performance-Analyse. Erweiterte Plattformen wie Sistrix oder Ahrefs liefern zusätzliche Keyword- und Linkdaten.
| Tool | Funktion | Preis | Besonderheit |
|---|---|---|---|
| Google Search Console | Indexierung, Crawling, Core Web Vitals, Mobile Usability | Kostenlos | Offizielle Google-Daten, unverzichtbar als Basis |
| Screaming Frog SEO Spider | Vollständiger Website-Crawl, Fehler-Erkennung | Kostenlos bis 500 URLs, kostenpflichtig ab ca. 149 EUR/Jahr | Branchenstandard für Site-Crawls |
| Google PageSpeed Insights | Core Web Vitals, Lighthouse-Analyse | Kostenlos | Zeigt Feld- und Labordaten, direkte Google-Empfehlungen |
| Sistrix | Keyword-Rankings, technische Analyse, Sichtbarkeitsindex | Ab ca. 99 EUR/Monat | Marktführer im DACH-Raum, starkes Sichtbarkeits-Tracking |
| Ryte | Technischer Crawl, Content-Qualität, Monitoring | Ab ca. 99 EUR/Monat | Stärken bei Monitoring und Benachrichtigungen |
| Ahrefs Site Audit | Cloud-basierter Crawl, Site-Health-Score, Backlink-Daten | Ab ca. 119 USD/Monat | Kombination aus technischen und Link-Daten in einer Plattform |
| Semrush Site Audit | Technischer Crawl, Issue-Tracking über Zeit | Ab ca. 119 USD/Monat | Gutes Reporting und automatisches Monitoring |
| Rank Math | WordPress-SEO-Plugin, Canonical, Schema, Sitemap | Kostenlos (Pro-Version verfügbar) | Einfache technische SEO-Grundlagen direkt im WP-Backend |
Für die meisten Websites reicht die Kombination aus Google Search Console, Screaming Frog und Google PageSpeed Insights für einen vollständigen technischen Audit aus. Sistrix oder Ahrefs lohnen sich vor allem, wenn Rankings und Backlinks dauerhaft beobachtet werden sollen.
Technisches SEO Checkliste 2026: 20 Punkte für Ihre Website
Nutzen Sie diese Checkliste, um die wichtigsten technischen Prüfpunkte in der richtigen Reihenfolge abzuarbeiten. Kritische Fehler, die die Indexierung blockieren, stehen an erster Stelle.
> Diese 5 Punkte zuerst:
> 1. robots.txt prüfen: kein versehentliches `Disallow: /`
> 2. SSL-Zertifikat gültig und aktiv
> 3. Alle wichtigen Seiten im Index (keine unbeabsichtigten noindex-Tags)
> 4. XML-Sitemap in der Google Search Console eingereicht
> 5. Keine 5xx-Serverfehler auf wichtigen Seiten
Crawling und Indexierung:
- robots.txt geprüft, keine wichtigen Verzeichnisse oder Ressourcen blockiert
- XML-Sitemap vorhanden, eingereicht und enthält nur indexierbare Live-URLs
- Google Search Console zeigt keine unerwarteten „Gecrawlt, aber nicht indexiert“-Seiten
- Kein versehentlicher noindex-Tag auf wichtigen Seiten
- Crawl-Budget bei Seiten mit 1.000+ URLs bewusst gesteuert
Website-Struktur und HTTPS:
- Wichtige Seiten maximal 3 Klicks von der Startseite entfernt
- URL-Format: kleingeschrieben, Bindestriche, keine unnötigen Parameter
- HTTP leitet vollständig und konsistent auf HTTPS um
- Keine Mixed-Content-Warnungen (HTTP-Ressourcen auf HTTPS-Seiten)
- www und non-www konsequent auf eine Version vereinheitlicht
Performance und Mobile:
- LCP unter 2,5 s auf mobilen Geräten (wichtigste Seiten)
- CLS unter 0,1 auf mobilen Geräten
- INP unter 200 ms auf mobilen Geräten
- Viewport-Meta-Tag auf allen Seiten vorhanden
- Mobile Benutzerfreundlichkeit in der Search Console ohne offene Fehler
Duplicate Content und Markup:
- Alle indexierbaren Seiten haben einen korrekten Canonical Tag
- Keine Weiterleitungsketten mit mehr als einem Hop
- Article- oder BlogPosting-Schema auf redaktionellen Seiten implementiert
- BreadcrumbList-Schema validiert und fehlerfrei
- Kein Seiteninhalt nur auf Desktop sichtbar (Inhaltsparität sicherstellen)
Häufige Fehler beim technischen SEO und wie Sie sie vermeiden
Viele technische SEO-Fehler entstehen nicht durch Fahrlässigkeit, sondern durch Standardverhalten von CMS-Systemen, Plugin-Updates oder Migrations-Prozessen. Die folgende Tabelle zeigt die häufigsten Probleme mit konkreten Lösungsansätzen.
| Fehler | Ursache | Lösung |
|---|---|---|
| Noindex-Tag auf Live-Seiten | Staging-Einstellung versehentlich auf Produktion übertragen | Search-Console-Coverage-Bericht prüfen; noindex-Tag aus Template oder Plugin-Einstellung entfernen |
| XML-Sitemap enthält 404-URLs | Gelöschte Seiten wurden nicht aus der Sitemap entfernt | Sitemap-Generator auf noindex- und Redirect-Filterung prüfen; tote URLs manuell entfernen |
| Weiterleitungsketten | Mehrfache URL-Umstrukturierungen ohne Konsolidierung | Screaming Frog Redirect-Ketten exportieren und alle auf direkte 301-Weiterleitungen kürzen |
| CLS durch Bilder ohne Dimensionen | Fehlende width/height-Attribute im HTML | Alle Bilder mit expliziten Breiten- und Höhenangaben versehen, besonders im Hero-Bereich |
| Mixed Content auf HTTPS-Seiten | Alte HTTP-Links zu Bildern oder Scripts nicht aktualisiert | Chrome DevTools Console auf Mixed-Content-Fehler prüfen; alle Ressourcen-URLs auf HTTPS umstellen |
| Canonical zeigt auf weiterleitende URL | Canonical wurde bei URL-Änderungen nicht aktualisiert | Screaming Frog Canonical-Spalte mit Status-Code-Spalte abgleichen; Canonicals auf finale URLs setzen |
| Seiten ohne interne Links | Neue Seiten erstellt ohne Verlinkung im Bestand | Screaming Frog Crawl mit Sitemap-Export abgleichen; kontextuelle Links von thematisch passenden Seiten setzen |
Häufige Fragen zu technischem SEO
Was ist der Unterschied zwischen technischem SEO und OnPage-SEO?
Technisches SEO befasst sich mit der Infrastruktur: Kann Googlebot die Seite crawlen, indexieren und rendern? OnPage-SEO kümmert sich um den Inhalt: Ist der Text relevant, gut strukturiert und für die Ziel-Keywords optimiert? Beide Bereiche beeinflussen das Ranking, aber technische Probleme sollten zuerst behoben werden. Inhalte zu optimieren, die Google nicht richtig indexieren kann, ist verlorene Arbeit.
Wie oft sollte man ein technisches SEO Audit durchführen?
Für die meisten aktiven Websites empfiehlt sich ein vollständiges technisches Audit einmal pro Quartal. Große E-Commerce-Seiten mit häufigen Inhaltsaktualisierungen sollten monatlich einen Crawl-Level-Check durchführen. Nach jedem Relaunch, CMS-Wechsel oder Hosting-Umzug ist ein sofortiger Audit innerhalb von 48 Stunden nach dem Launch Pflicht. Auch ein unerklärlicher Traffic-Einbruch ist ein guter Anlass für einen ungeplanten Audit.
Wie lange dauert ein technisches SEO Audit?
Für eine Website mit unter 500 Seiten planen Sie ein bis zwei Tage ein. Für mittelgroße Seiten mit 500 bis 5.000 Seiten rechnen Sie drei bis fünf Tage. Große Seiten mit zehntausenden URLs benötigen ein bis zwei Wochen, besonders wenn Log-File-Analyse und JavaScript-Rendering-Checks einbezogen werden. Die Dauer skaliert vor allem mit der Seitenanzahl, nicht mit der Komplexität der Site.
Welches Tool ist für ein technisches SEO Audit unverzichtbar?
Die Google Search Console ist das wichtigste Einzel-Tool für technisches SEO. Sie liefert offizielle Crawling- und Indexierungsdaten, Core-Web-Vitals-Felddaten, Mobile-Usability-Probleme und Informationen zu manuellen Maßnahmen von Google. Kein anderes Tool liefert direktere Daten darüber, wie Google eine Website tatsächlich sieht. Screaming Frog ergänzt die Search Console mit einem vollständigen Website-Crawl aus Crawler-Perspektive.
Was ist das Crawl-Budget und warum ist es wichtig?
Das Crawl-Budget beschreibt, wie viele URLs Googlebot innerhalb eines bestimmten Zeitraums auf einer Website crawlt. Bei kleinen Websites ist das kein relevantes Thema. Bei Seiten ab mehreren tausend URLs kann verschwendetes Crawl-Budget dazu führen, dass wichtige neue Seiten wochenlang nicht indexiert werden, weil Googlebot sein Budget auf Parameter-URLs, doppelten Content oder Fehlerseiten verwendet.
Braucht man einen Entwickler, um technische SEO-Fehler zu beheben?
Viele Probleme lassen sich direkt im CMS oder über ein SEO-Plugin beheben: noindex-Tags entfernen, Canonical Tags setzen, XML-Sitemap einreichen, robots.txt anpassen. Komplexere Themen wie JavaScript-Rendering-Probleme, serverseitige Weiterleitungsregeln und Performance-Optimierungen erfordern Entwickler-Unterstützung. Beheben Sie zunächst, was ohne Entwickler geht, und priorisieren Sie die restlichen Punkte klar nach Traffic-Auswirkung für die Übergabe.